pandas练习答案:创建虚拟环境,爬取数据并进行分析
pandas练习:
使用爬虫工具爬取淘客网站上“咖啡”的销售数据,然后使用pandas进行分析。
淘客网站:https://www.dataoke.com/xp/qlist
爬虫地址:Home - 计算机视觉教程
练习1:处理异常值,将“品牌”列中缺失的数据填充为“其他”
提示:使用fillna()方法,参考7.5.3
练习2:将数据按照“总销量”排序
提示:使用df.sort_values()方法,参考7.3.7
练习3:选取“总销量”大于10000的商品
提示:参考7.4.4布尔索引
练习4:计算售价的平均数,中位数
提示:
1、使用df['券后价']将“券后价”列转化为Series,参考7.4.1
2、然后使用.mean(),.median()方法计算平均数和中位数,参考7.6.1统计操作
练习5:统计品牌上榜次数
提示:
1、使用df['品牌']将品牌列转化为Series,参考7.4.1
2、然后使用value_counts()方法,计算Series中每个唯一值出现的频率,参考7.6.4
练习6:查看“雀巢”,“瑞幸咖啡”,“g 7 coffee”三个品牌的销售数据
提示:使用isin()方法,参考7.4.4布尔索引
答案:
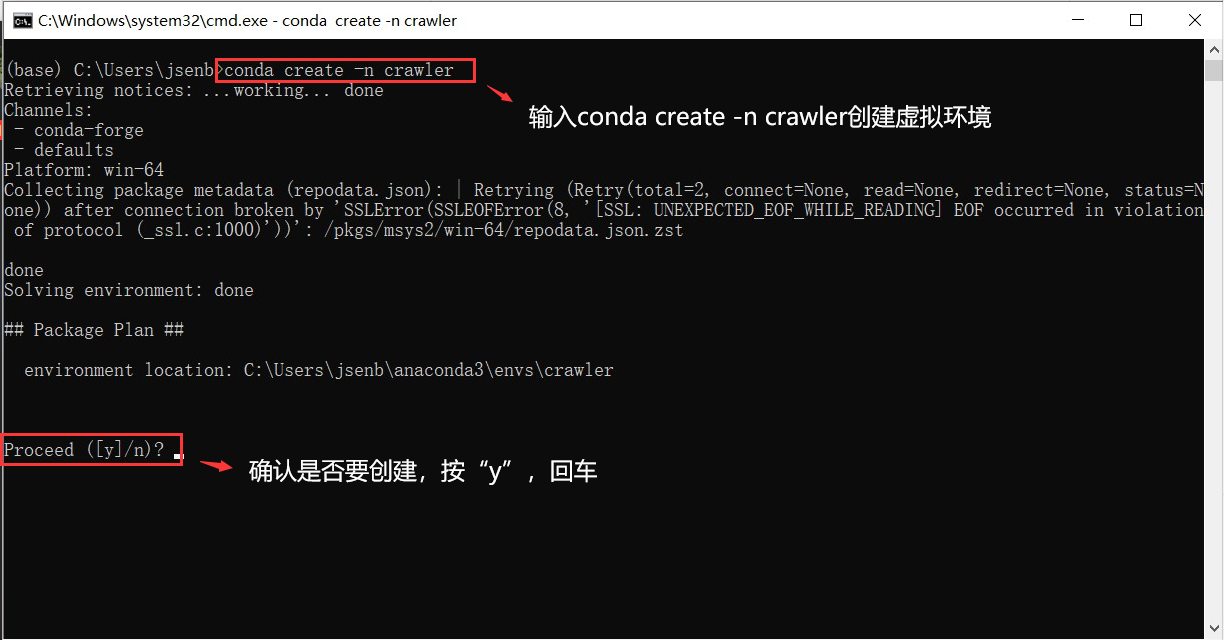
1、使用conda新建一个名为“crawler”的虚拟环境(注:虚拟环境的名字可以按自己需求命名)
打开anaconda:
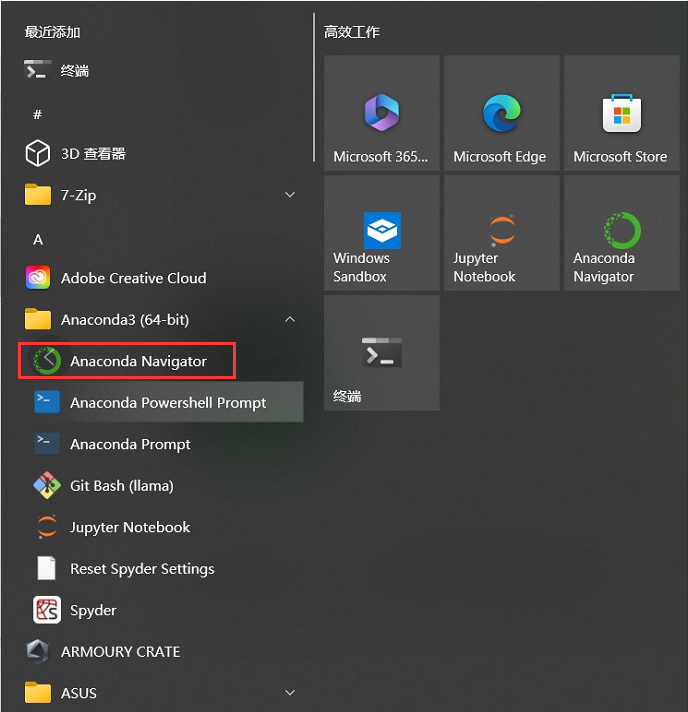
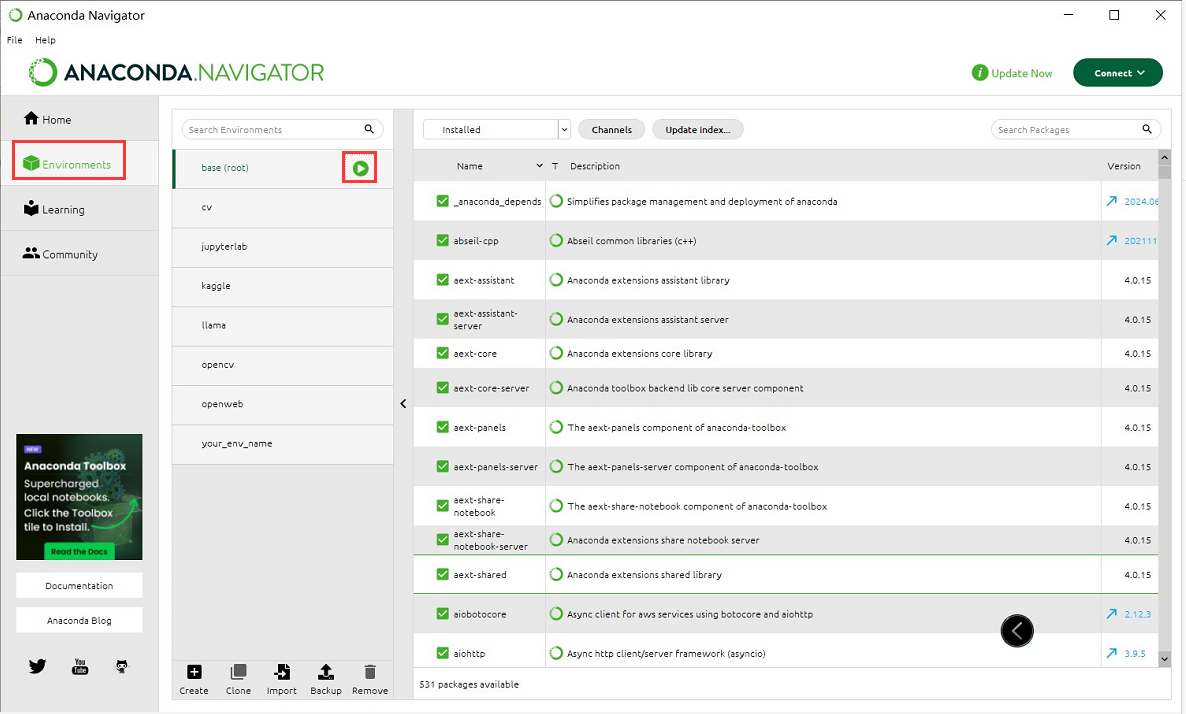
进入conda base环境
创建虚拟环境,输入
conda create -n crawler
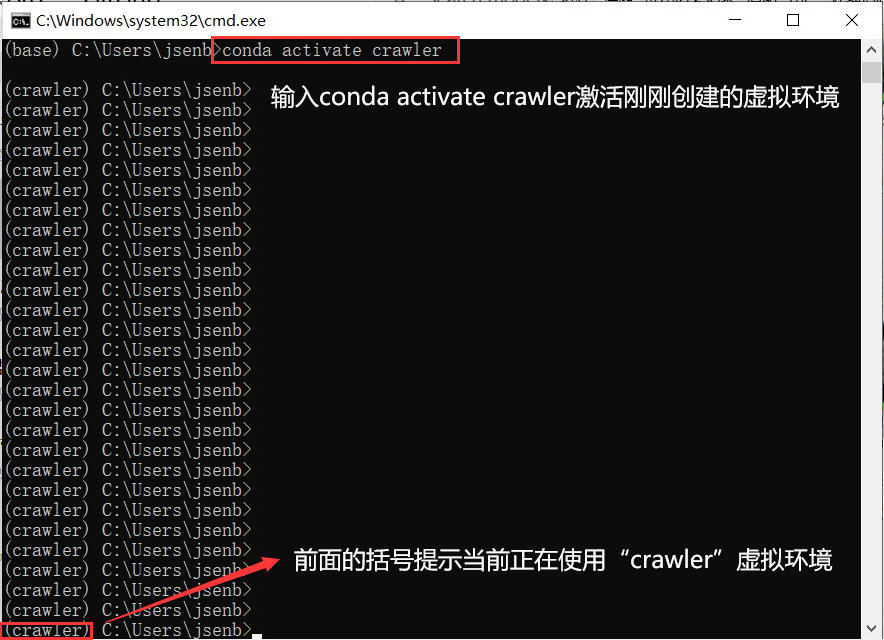
2、激活虚拟环境,输入:
conda activate crawler
3、将pip的源服务器修改为国内服务器,让安装速度更快
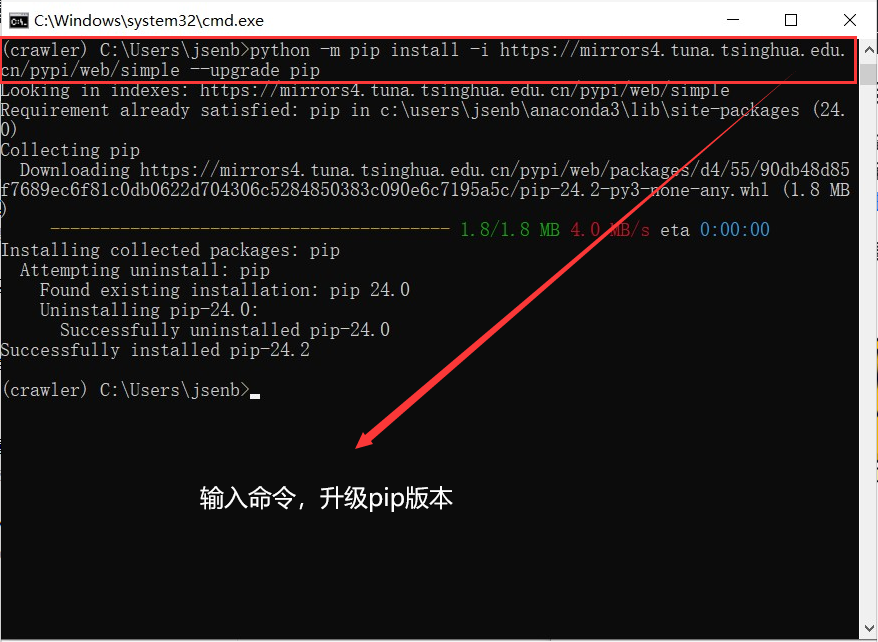
升级 pip 到最新的版本:
python -m pip install -i https://mirrors4.tuna.tsinghua.edu.cn/pypi/web/simple --upgrade pip
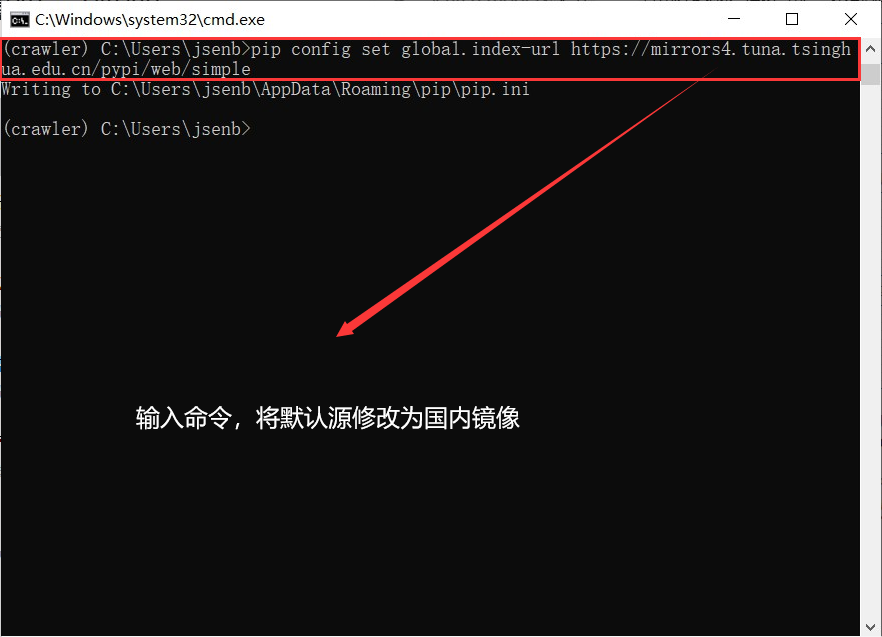
将默认的源替换为清华大学镜像站
pip config set global.index-url https://mirrors4.tuna.tsinghua.edu.cn/pypi/web/simple
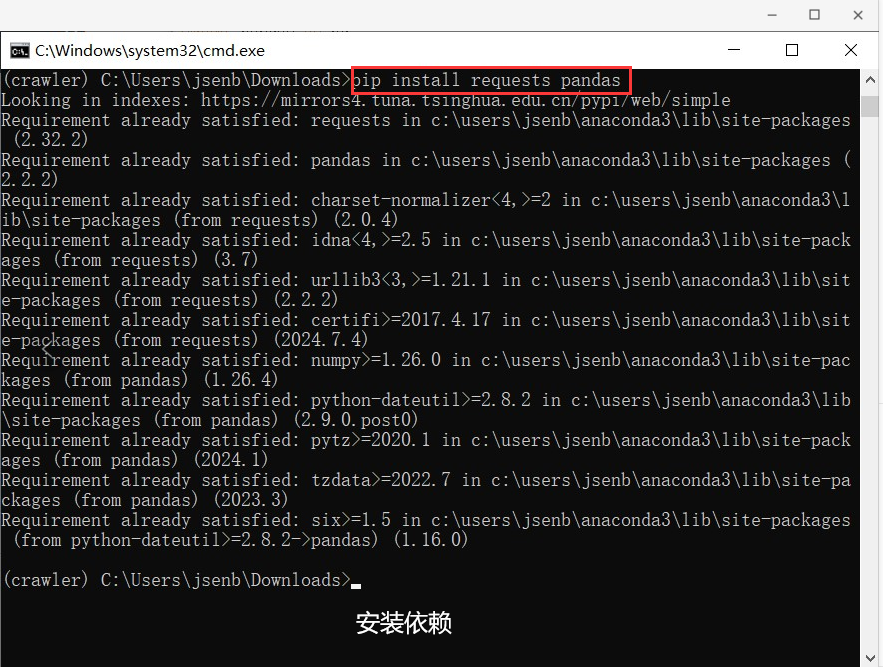
4、安装依赖
输入命令:pip install requests pandas
5、下载爬虫程序,使用cd命令将命令行的工作路径切换到python程序所在文件夹
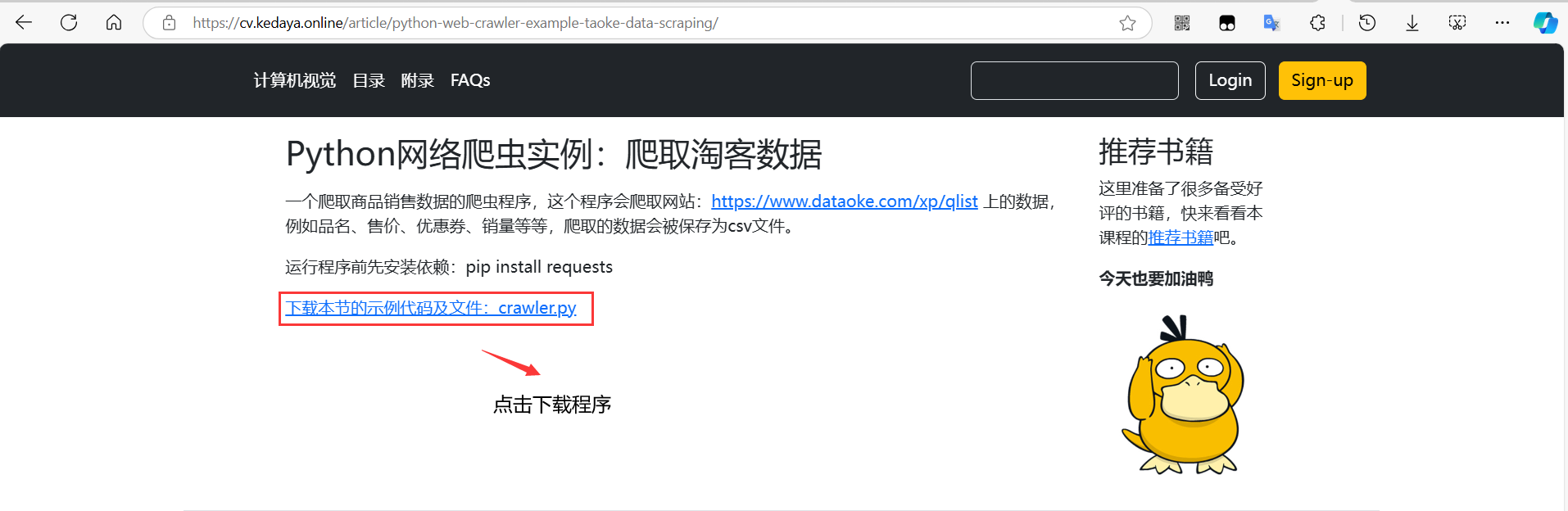
找到下载的文件,右键点击,查看文件所在文件夹
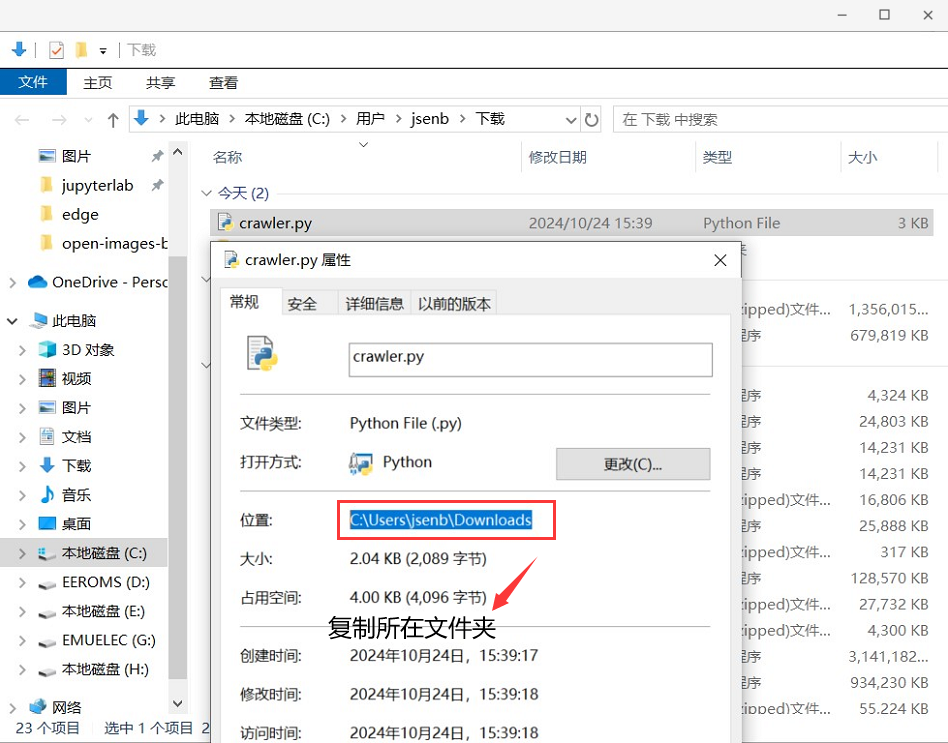
使用cd命令(change directory)修改当前工作目录:
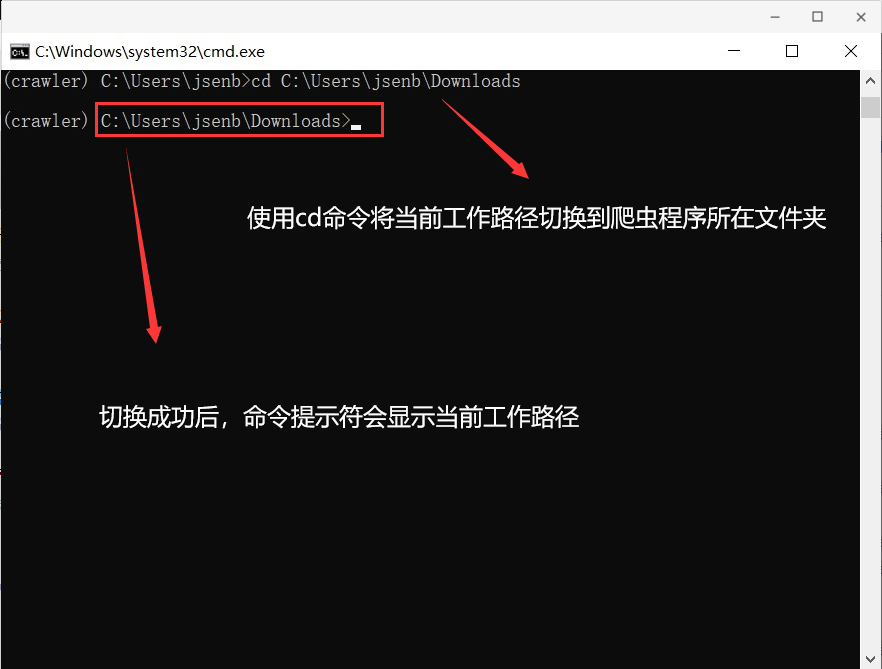
运行爬虫程序:python crawler.py
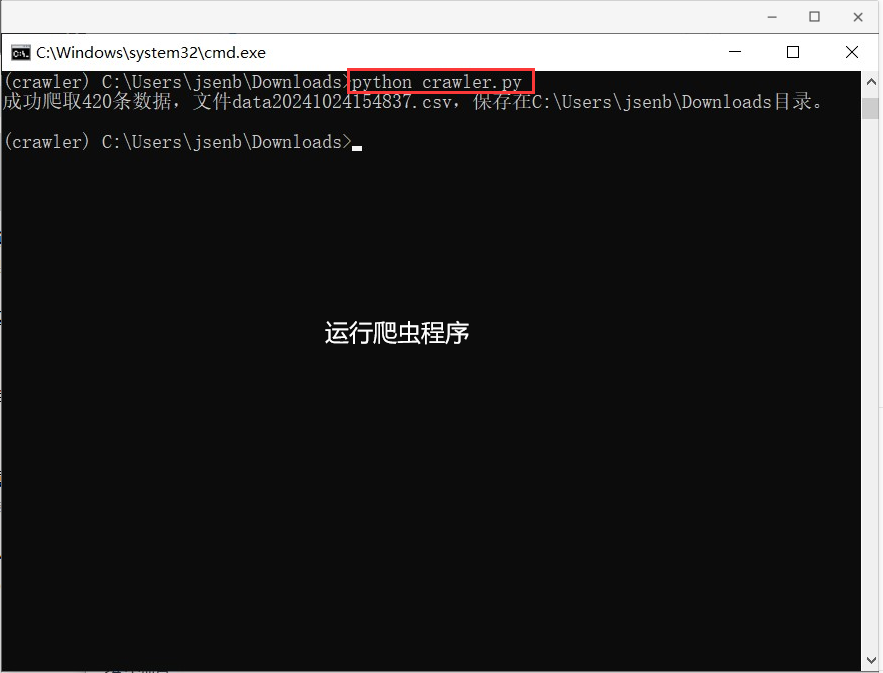
7、打开Python IDLE编写Python程序,对数据进行分析,也可以换成你自己喜欢的集成开发环境或者编辑器,
注意:我们只使用Python IDLE编辑代码,不使用Python IDLE运行代码,因为Python IDLE使用的是系统的Python环境,而我们的依赖库:requests、pandas安装在conda虚拟环境中,所以我们需要使用conda环境运行Python程序。
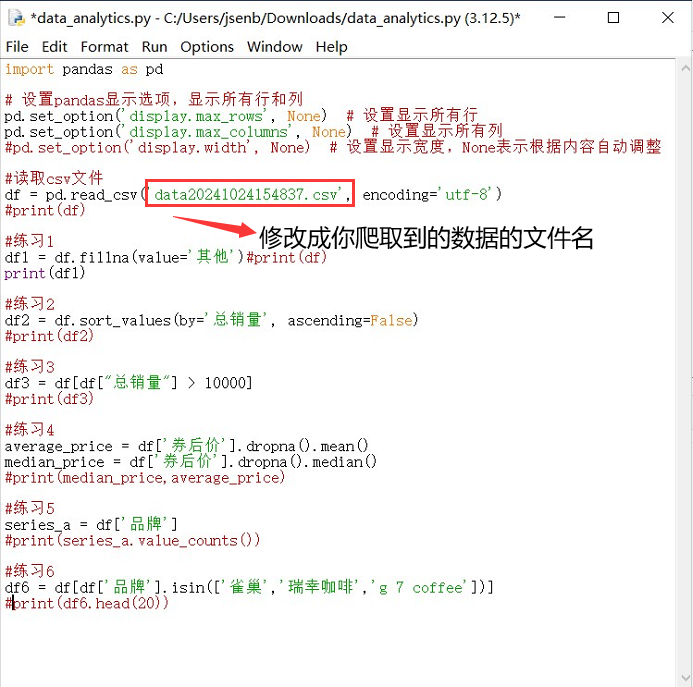
将Python程序文件保存在刚刚爬取的数据文件同一文件夹下,注意将csv文件提供成你的文件名
8、在conda环境中运行刚刚编写的数据分析程序
python data_analytics.py
Tip:可以使用注释,每次只输出一个结果,便于查看。
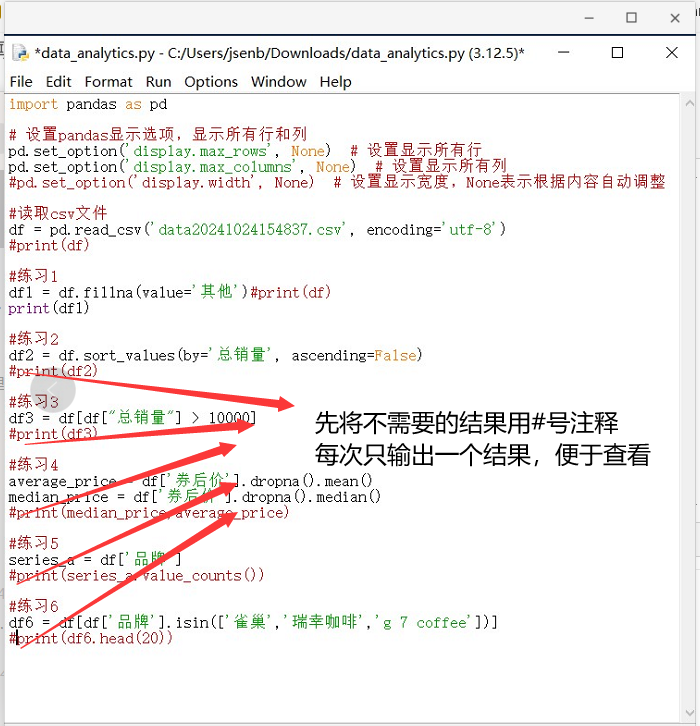
作业代码如下:
import pandas as pd
# 设置pandas显示选项,显示所有行和列
pd.set_option('display.max_rows', None) # 设置显示所有行
pd.set_option('display.max_columns', None) # 设置显示所有列
#pd.set_option('display.width', None) # 设置显示宽度,None表示根据内容自动调整
#读取csv文件
df = pd.read_csv('data20241024154837.csv', encoding='utf-8')
print(df)
#练习1
df1 = df.fillna(value='其他')#print(df)
print(df1)
#练习2
df2 = df.sort_values(by='总销量', ascending=False)
print(df2)
#练习3
df3 = df[df["总销量"] > 10000]
print(df3)
#练习4
average_price = df['券后价'].dropna().mean()
median_price = df['券后价'].dropna().median()
print(median_price,average_price)
#练习5
series_a = df['品牌']
print(series_a.value_counts())
#练习6
df6 = df[df['品牌'].isin(['雀巢','瑞幸咖啡','g 7 coffee'])]
print(df6.head(20))
今天也要加油鸭
