图像语义分割
14 图像语义分割
14.1 什么是图像语义分割
图像语义分割是一种像素级别的分类,旨在为图像中的每个像素分配一个类别标签,从而识别并分割出图像中不同的对象和场景。这种像素级别的分类使得模型能够理解图像内容的详细结构,区分出人、车辆、建筑物等不同实体,以及它们所属的类别。语义分割对于自动驾驶、机器人导航、医疗影像分析等领域具有重要应用价值,它要求模型不仅要识别出图像中的物体,还要精确地知道物体在图像中的确切位置。
图1

14.2 图像语义分割常用的数据集
图像语义分割与目标检测不同,训练模型时需要使用像素级别标注的数据集,图像语义分割常用的数据集如下:
- Pascal VOC2012数据集是一个由欧盟资助的广泛应用于计算机视觉领域的一个基准数据集,该数据集共包含20个类别,11,530张图片,27,450个标注框,对于分割任务,训练集包含1464张图片,验证集包含1449张图片,共6,929个语义分割。
- Cityscapes数据集是一个专为城市街景设计的图像语义分割数据集,它包含了5000张高质量的城市景观图片,这些图片涵盖了50个不同的城市。每张图片都有精细的像素级别的标注,涵盖了30个类别,包括不同的车辆、行人、道路、建筑物等城市元素。该数据集旨在推动城市场景理解技术的发展,特别是在自动驾驶和街景分析等应用领域。
- ADE20K是一个通用的场景分割数据集,由 MIT Computer Vision Lab 发布。该数据集包含超过 20,000 张高质量的图像,每张图像都被细致地标注,覆盖 150 类常见物体和场景类别,包括建筑物、道路、家具、自然景观等。ADE20K 不仅适用于语义分割,还可以支持场景识别和实例分割任务。其标注粒度细腻,能够区分同一类别中不同实例的细节,是目前最全面和多样化的语义分割数据集之一,广泛用于模型训练和性能评估。
14.3 U-Net
假如我们需要预测图片中,某个像素对应的类别。如果我们按照之前学习的目标检测的方法,我们会将图像先传入一个预训练模型(VGG16或者ResNet),然后我们会将输出展平,得到目标的类别和对应的边界框偏移值,但是在图像分割的情况下,输出形状与输入图像的形状是相同的,我们是在原图像的尺寸上标注像素的类别值,如果展平卷积层的输出然后重建图像可能会导致信息丢失,所以我们需要一种神经网络模型来进行图片语义分割,而这个神经网络模型必须具备以下两个特点: 1. 原始图像中物体的形状和结构在分割输出中保持不变 2. 全卷积架构(而不是展平某个层),输入一张图像,输出一张图像(而不是类别与偏移量)
U-Net是一种经典的卷积神经网络架构,最早出自2015年MICCAI医学图像顶级会议中,最初设计用于生物医学图像分割任务。它以U型结构命名,由对称的编码器和解码器组成。编码器提取图像的多尺度特征,解码器逐步恢复特征的空间分辨率。U-Net 的关键特性是使用跳跃连接,将编码器的特征与解码器的对应层融合,从而保留更多的细节信息。U-Net模型在小规模数据集上也能表现出色,因其有效的上下文捕获能力,已被广泛应用于医学影像分析、遥感图像处理和场景解析等领域。
14.3.1 U-Net模型的训练过程
图2
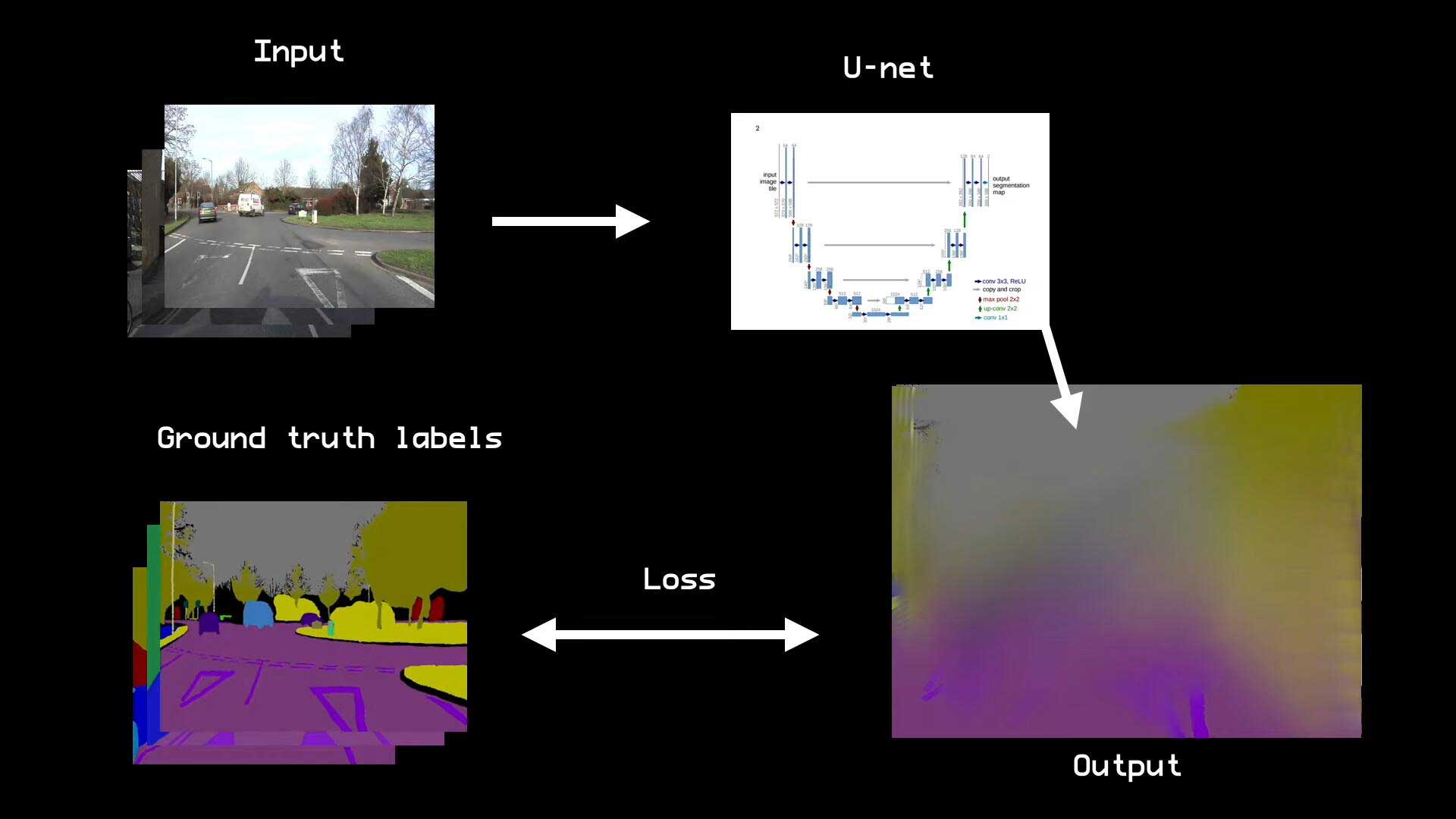
如上图所示,将输入图像传入U-Net模型,计算得到输出值,将输出值与数据集的标注值进行比较,并计算损失值,然后通过梯度下降的方法,调整权重参数,使损失值下降,重复迭代以上步骤,直到模型训练完成。
14.3.2 U-Net模型的结构
图3
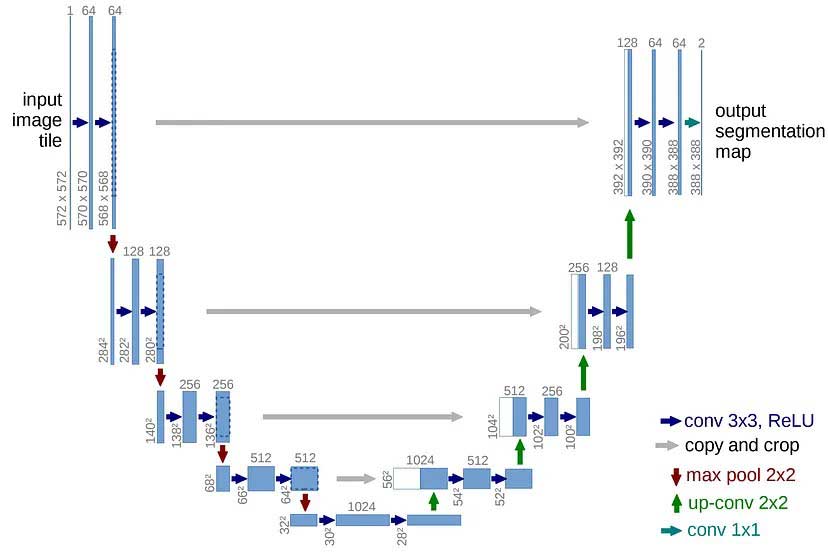
U-Net模型的结构如图3所示,U-Net模型的形状像U字形。U-Net模型的左边部分,是一系列卷积层和池化层,输入图像在卷积和池化的过程中,图像的大小不断减小,通道数不断增加。在U-Net模型的右边部分,小尺寸的特征图被逐步放大到接近原图片的尺寸,输出的通道数与类别数一样多。
此外,在放大的过程中,我们还利用左半部分对应层的信息,通过跳跃连接(类似残差网络ResNet中的跳跃连接),以便我们可以保留原始图像中的结构/物体。这样,U-Net架构学会了保留原始图像的结构(和物体的形状),同时利用卷积的特征来预测对应于每个像素的类别。
14.3.3 U-Net模型的训练过程
- 图3中,蓝色的箭头表示卷积与ReLU激活操作,第一个蓝色箭头的卷积层,输入的图像尺寸为572572,通道数为1(即1张黑白图像),经64个331的卷积核卷积操作之后,输出的尺寸为570570,64通道。
- 灰色的箭头表示U-Net模型的Copy and Crop操作,U-Net模型左边编码器的高分辨率特征包含了图像的边缘信息和局部细节,这些信息对语义分割至关重要,但是编码器中的特征图逐层经过池化操作,其大小会逐渐减小,这样会与右边解码器中的特征图大小不匹配,为了将编码器特征与解码器特征结合,需要将将编码器的特征图裁剪到与解码器特征图相同的大小(Crop裁剪),然后将裁剪后的特征图直接复制并与解码器对应层的特征图进行拼接(Copy复制)。
- 红色箭头表示2*2最大值池化,最大值池化后,图片的尺寸缩小为原尺寸的一半,图层的通道数不变。
- 绿色的箭头代表反卷积(Up-Conv),在U-Net架构中,会对特征图进行反卷积,反卷积会是特征图的尺寸逐步放大,其计算过程如下:
图4
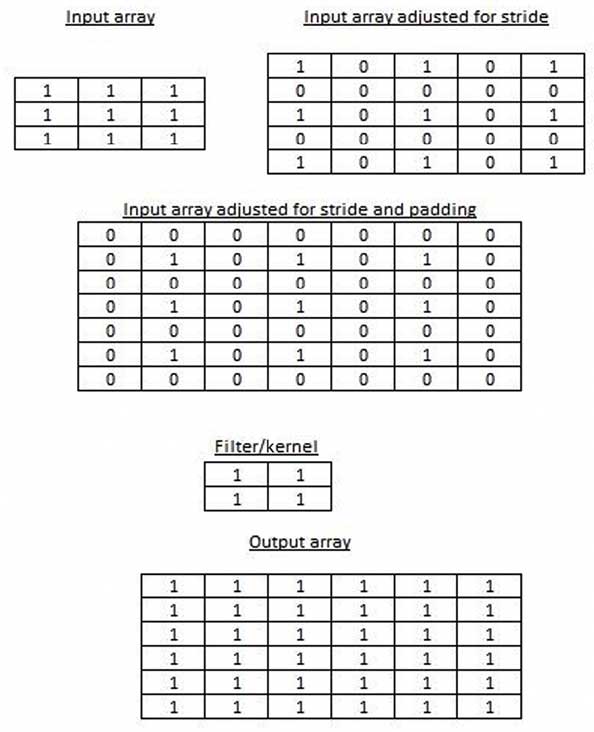
首先针对步长(stride)对特征图进行调整和填充,在反卷积中,步长用于确定输出尺寸相对于输入的增大程度。一般步长设置为 2 时,输出图像的高宽会是输入图像的 2 倍。然后再进行卷积,33的输入就会被放大,得到一个66的输出。
- 蓝绿色箭头表示使用11的卷积来调整特征图的通道,11的卷积不会改变特征图的大小,我们可以根据需要使用特定数量的卷积核数量来调整通道数。
今天也要加油鸭
