图像生成
15 图像生成
图像生成(Image Generation)是一种计算机视觉任务,其目的是根据输入生成具有目标图像性质的图像。这种任务在深度学习领域非常重要,因为它可以用于各种应用,如生成人脸、物体识别、风格转换等。
15.1 基本原理
图像生成分为传统图像生成和基于深度学习的图像生成两个方向,我们主要介绍基于深度学习的图像生成。图像生成是通过训练深度学习模型,使其能够学习训练数据中的分布特征,从而生成与数据分布相似或符合特定要求的新图像。模型通常从一个潜在空间(如随机噪声)或条件输入(如文本描述或标签)中采样,并通过一系列非线性变换逐步构建输出图像。常见的模型如变分自编码器(VAE)通过潜在空间的概率建模生成多样化的图像。这些模型通过优化目标函数,使生成结果尽可能接近真实数据的分布。生成对抗网络(GANs)通过生成器和判别器的对抗训练提高生成图像的质量,而变分自编码器(VAE)通过潜在空间的概率建模生成多样化的图像。这些模型通过优化目标函数,使生成结果尽可能接近真实数据的分布。
15.2 变分自编码器
15.2.1 自编码器
自编码器是一种无监督学习的神经网络模型,主要用于数据降维和特征学习。它由两个主要部分组成:编码器和解码器。编码器将输入数据压缩成一个低维的潜在表示(向量),而解码器则从这个潜在表示(向量)重建出原始数据。自编码器的目标是最小化输入数据与重建数据之间的差异,从而学习到数据的有效表示。自编码器可以用于多种任务,包括数据去噪、图像重建、异常检测和生成模型等。通过训练,自编码器能够提取出输入数据的关键特征,并在保持重要信息的同时去除冗余部分,使其在数据预处理和特征提取方面具有广泛的应用潜力。
图1
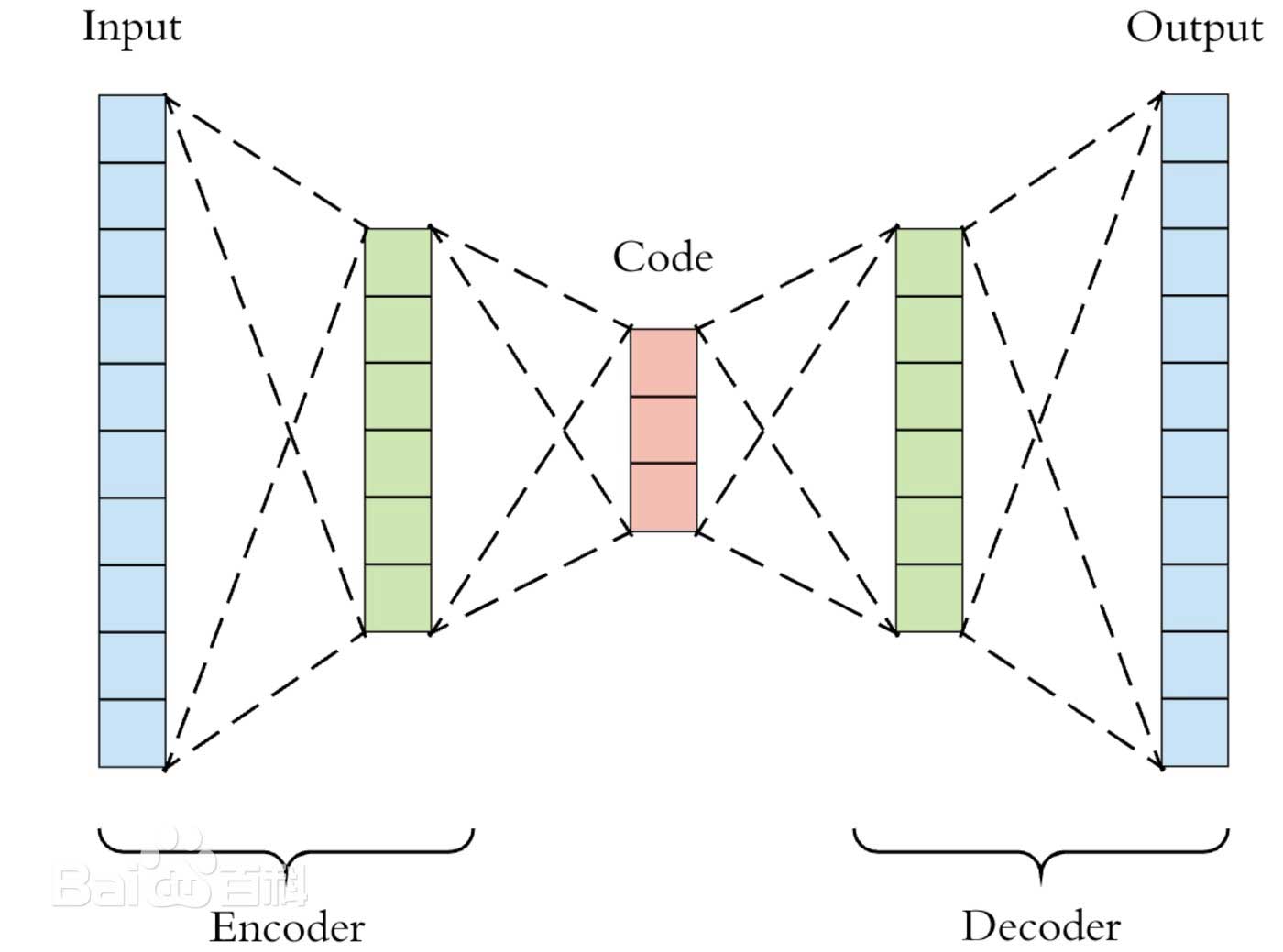
自编码器的工作原理如下:通过训练网络使输入数据尽可能精确地重现在网络的输出端。这一过程包括两个主要阶段:编码和解码。在编码阶段,自编码器的编码器部分将输入数据压缩成一个低维的潜在空间表示(向量),这个表示捕捉了输入数据的核心特征。随后,在解码阶段,解码器部分尝试从这个压缩的表示(向量)中重建原始输入数据。自编码器的训练目标是最小化输入和重建输出之间的差异,通常是通过计算两者之间的损失(如均方误差)并使用反向传播算法来调整网络权重,以此学习到数据的有效压缩和重建方式。通过这种方式,自编码器能够学习到数据的内在特征。
图2
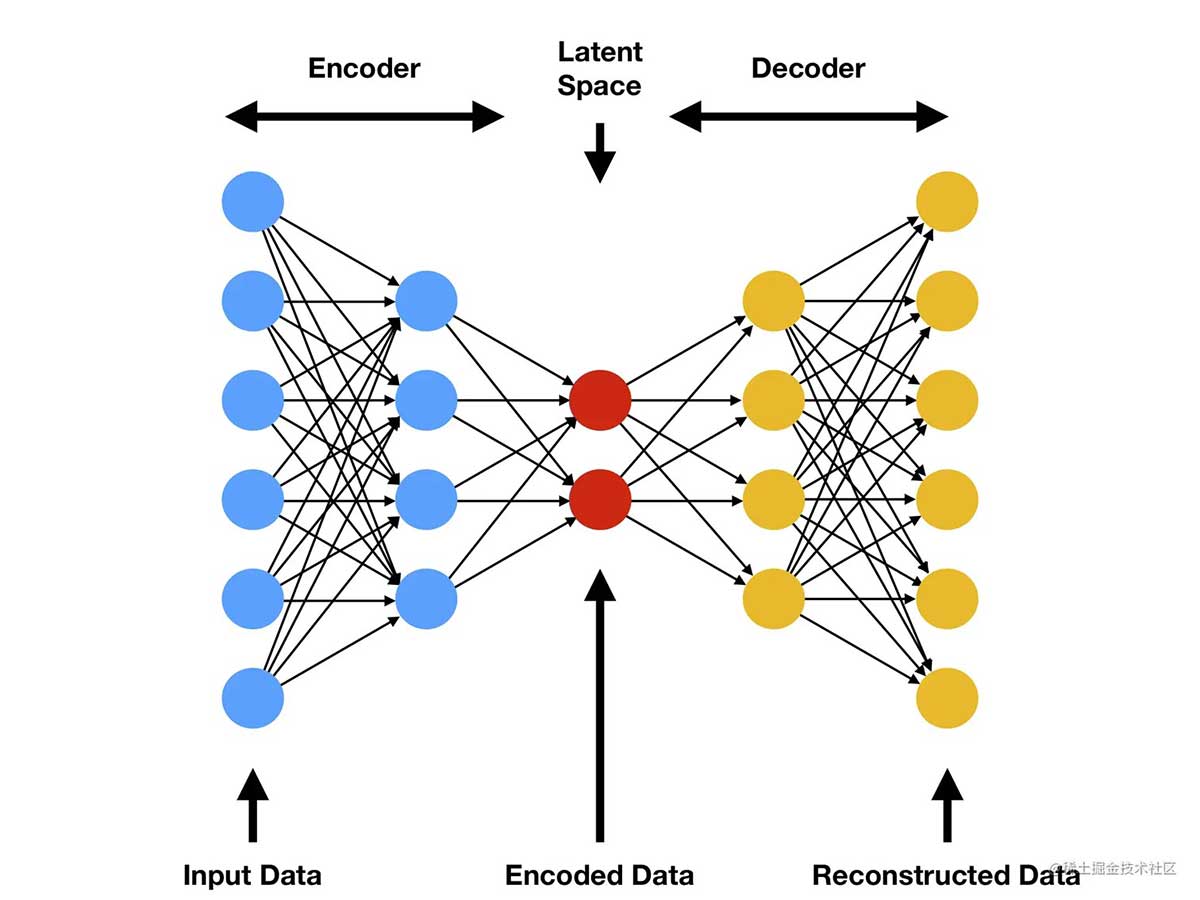
15.2.2 自编码器的局限性
如果我们有某张图片的编码向量,那么就可以利用训练好的自编码器重建该图像,如图3所示:
图3
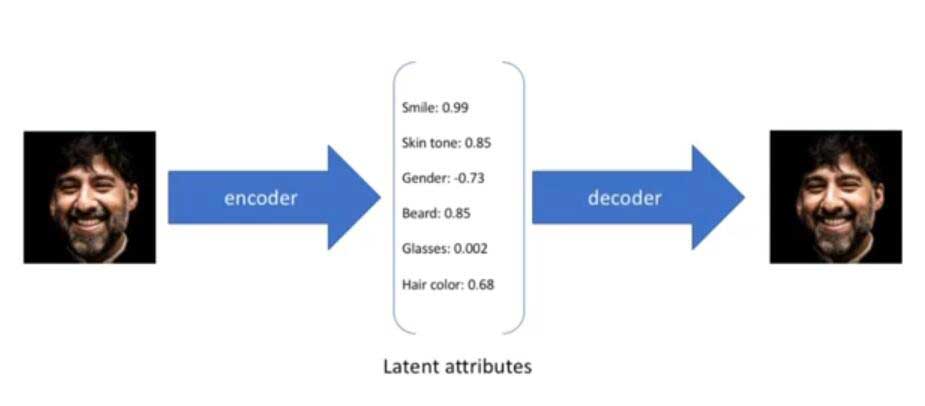
我们将一张图片输入到自编码器后,会得到这张在表情、肤色等特征上的取值的编码向量z,而解码器会根据这些特征取值重构出原始输入的这张面部图像。但是如果我们随机生成一个特征编码向量z,解码器并不能根据这个特征编码向量产生新的相应面部图片,因为自编码器训练的目的是使输出像素与输入像素尽可能相近,自编码器只能将输入图片产生的特征编码向量还原为输入图片。
图4

如上图所示,假设我们训练好的自编码器将“新月”图片编码为成code=1(这里假设code只有1维),将其code=1解码能得到“新月”的图片;将“满月”编码为code=10,同样将code=10解码能得到“满月”图片。这时候如果我们给自编码器一个code=5,我们希望是能得到“半月”的图片,但由于之前训练时并没有将“半月”的图片编码,也没有编码为5的其他图片,那么我们就不太可能得到“半月”的图片。因此自编码器多用于数据的压缩和恢复,用于数据生成时效果并不理想。
图5
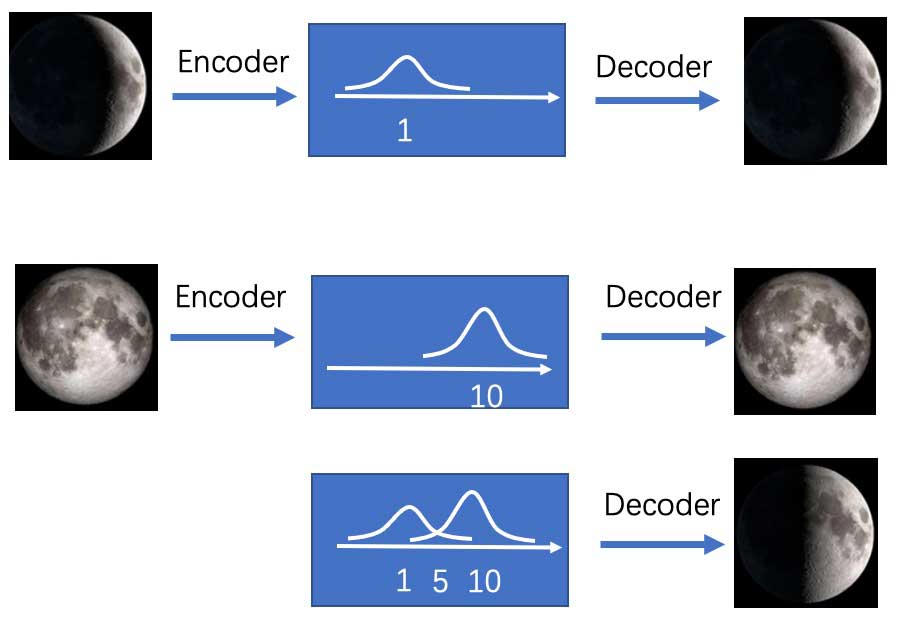
要改进这个问题,我们可以不将图片编码成“数值”,而将其编码成“分布”。还是刚刚的例子,我们将“新月”图片编码为μ=1的正态分布,那么就相当于在1附近加了噪声,此时不仅1表示“新月”,1附近的数值也表示“新月”,只是1的时候最像“新月”。将”满月”编码为μ=10的正态分布,10的附近也都表示“满月”。那么code=5时,就同时拥有了“新月”和“满月”的特点,那么这时候decode出来的大概率就是“半月”了。
15.2.3 重参数化
为了使生成的潜在向量在大体上服从单位高斯分布,我们要在自编码器的编码网络中加入一个约束,经过这样的 改进之后,我们只需要从单位高斯分布中采样一个潜在向量,并将其传到解码器(decoder)中,就可以生成新的图像了。
假设预设的分布为Q,隐含变量的分布为P,我们可以用KL散度来衡量两个概率分布的差异,其公式如下:
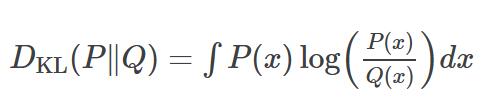
经推导,KL散度的损失函数为:
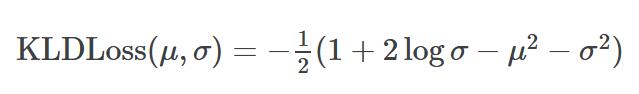
此时变分自编码器的损失函数由两部分组成:1.衡量模型重构图像精确度的均方误差。2.预设的概率分布和隐含变量的差异程度。
我们要让隐含变量服从正态分布zN(μ,σ),但在目标函数的优化过程中,变分自编码模型并没有用zN(μ,σ)采样得到隐变量z,因为这样的采样操作是无法求导的,所以无法进行反向传播。所以在求解时使用了一个小技巧:先采样一个标准正态分布,z~N(0,1),然后计算z = μ + εσ。这样得到的隐变量z仍然服从正态分布z~N(μ,σ),同时也可以正常对μ,σ进行求导,不会影响反向传播。
15.3 生成对抗网络(GAN)
你能区分出以下这些图片是真实的图片还是生成的图片吗?
项目地址:https://thispersondoesnotexist.com/
这个项目的名称为this person does not exist,翻译成中文就是“这个人并不存在”,项目中的图片都是使用生成对抗网络来生成的。
生成对抗网络(GAN)是一种深度学习架构,由Ian Goodfellow等人在2014年提出。它包含两个关键组件:生成器(Generator)和判别器(Discriminator)。生成器的目标是从随机噪声中生成与真实数据相似的数据,而判别器则尝试区分生成的数据和真实数据。这两个网络通过对抗式学习相互竞争:生成器努力生成越来越逼真的数据以“欺骗”判别器,而判别器则不断改进以更准确地识别真实与生成的数据。通过这种对抗训练,生成器最终能够产生高质量、难以区分真假的数据。GAN在图像生成、文本生成和音频生成等领域有非常出色的表现。
15.3.1 生成对抗网络的原理
图6
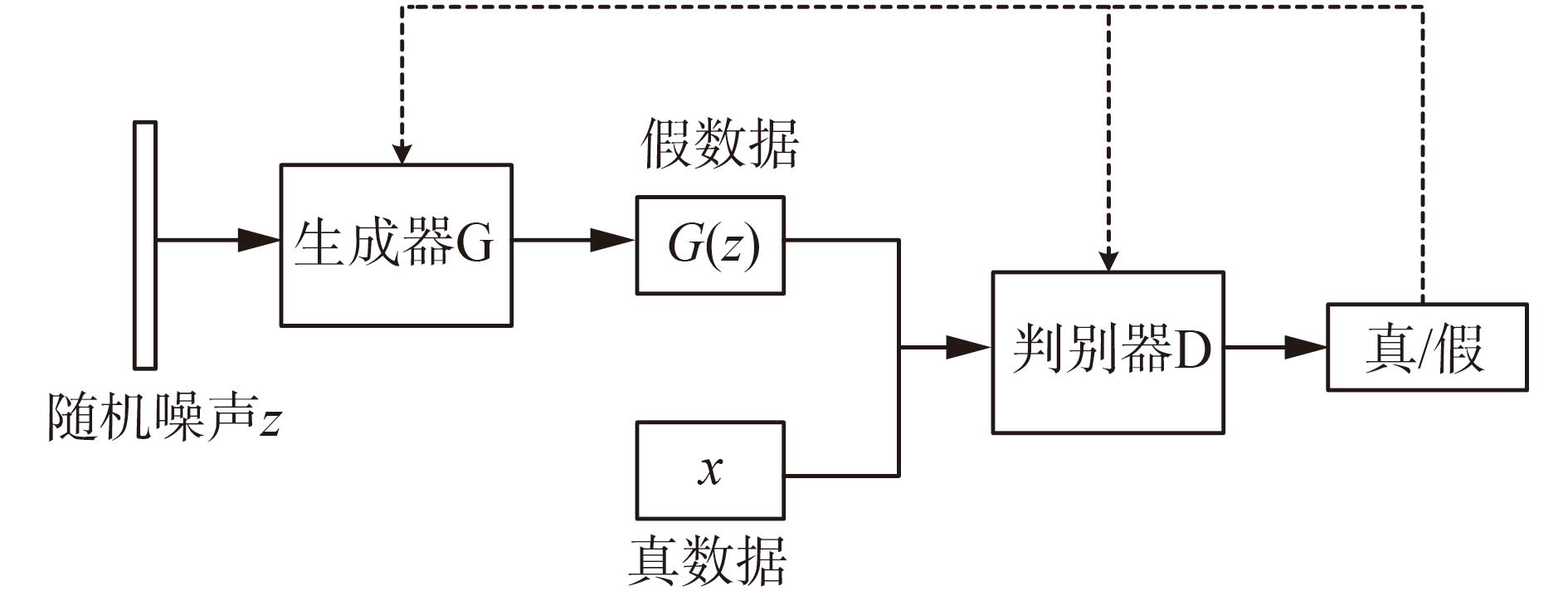
如上图所示,生成对抗网络包含生成器和判别器。
当训练生成器的时候,锁定判别器的权重。对于生成器而言,我们希望它生成的图片能骗过判别器,当输入的图片为生成的假数据(生成的图片)时,我们希望输出的值越接近1越好。我们将生成的图片传入模型,通过正向传播计算损失值,然后通过梯度下降来调整生成器的权重参数。
当训练判别器的时候,锁定生成器的权重。对于判别器而言,我们希望它能准确的识别图片是真实图片还是生成的图片,当输入的图片为真数据(真实图片)时,我们希望判别器的输出越接近1越好,反之,当输入的图片为假数据(生成的图片)时,我们希望判别器输出的值越接近0越好。
通过迭代训练生成器和判别器,使得生成器和判别器的能力不断增强,直到生成器能生成以假乱真的图片。
15.3.2 通过可视化的形式理解生成对抗网络
GAN Lab项目地址:https://poloclub.github.io/ganlab/
图7
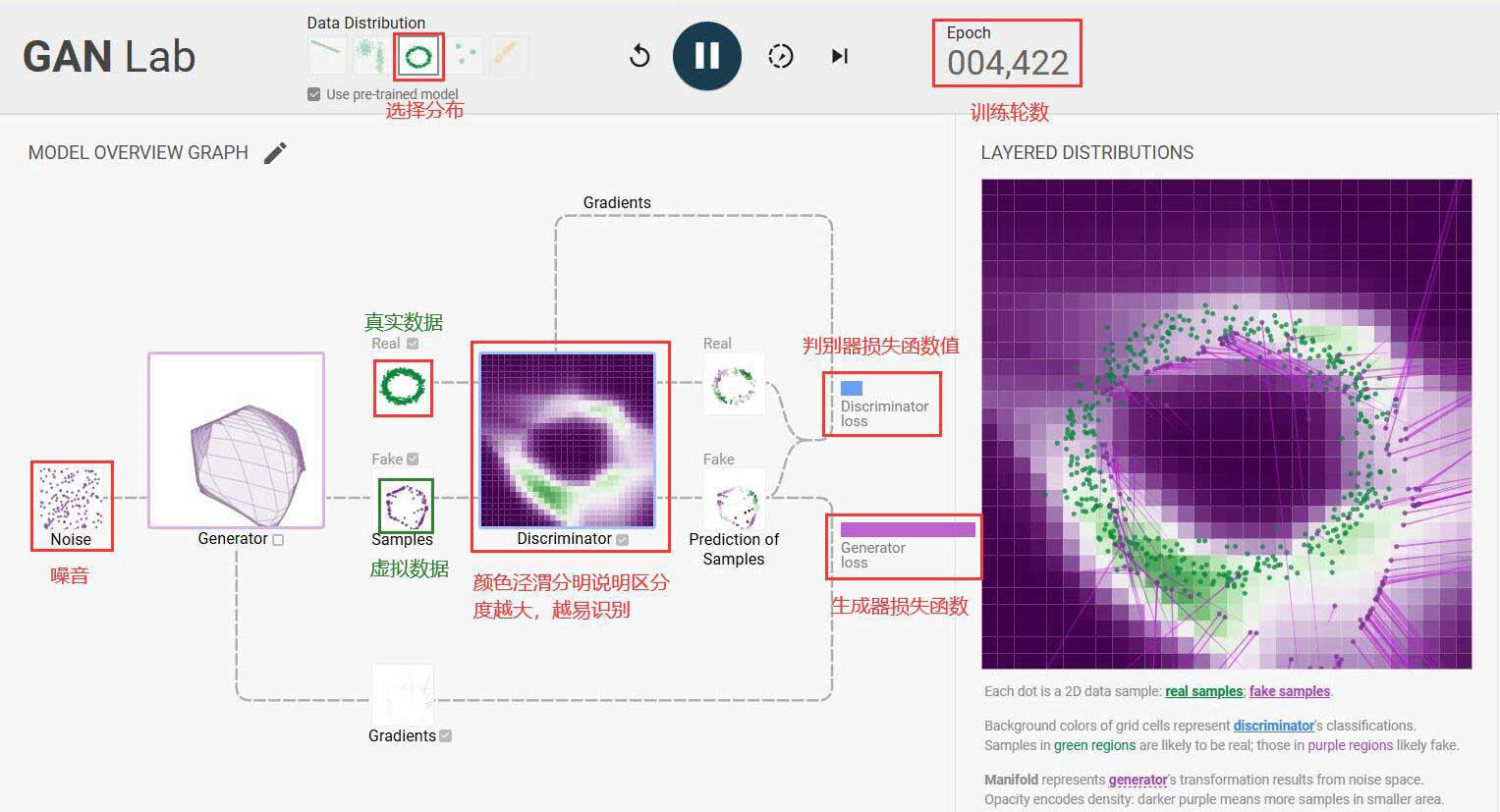
在这个项目中,我们可以使用项目提供的在线工具,对生成对抗网络的训练过程进行实时可视化,从而直观的理解生成对抗网络的训练过程。如图7所示,生成器根据噪音生成虚拟数据,然后于真实数据一起送到判别器进行判别,在模型训练的初始阶段,生成的虚拟数据也真实数据的差异非常大,判别器很容易识别生成的虚拟数据。然后在训练的过程中,判别器根据对应的损失函数值,调整判别器的连接权重,同样,生成器也根据对于的损失函数值,调整生成器的连接权重。随着训练的持续进行,之前清晰的紫绿色块逐渐消失,说明判别器已经无法判断谁为真数据,谁为假数据,虚拟数据和真实数据已经趋于一致。
今天也要加油鸭
