《计算机视觉》复习资料
绪论:
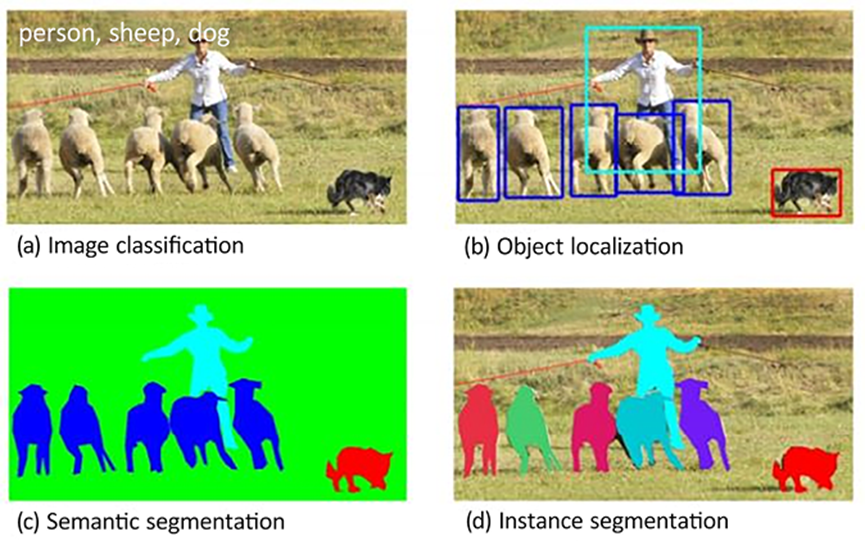
计算机视觉的主要任务及其应用:图像分类、对象检测、语义分割、图像生成。
人工智能发展的三大要素:数据、算法、算力
计算机视觉在自动驾驶领域的主要应用:环境感知、障碍物检测与分类、车道检测、交通标志和信号识别
数字图像处理:
传统计算机视觉的主要特点是:依赖手工提取特征。
常见的色彩空间:
HSV:以人类直观感受为媒介的颜色模型
RGB:以发光物体(显示器)为媒介的色彩模式
CMYK:以印刷(墨水)为媒介的颜色模型
常见图像的文件格式:
1、JPEG
JPEG(Joint Photographic Experts Group)格式是一种广泛使用的图像文件格式,以其有损压缩技术而闻名,能够在保持相对较高图像质量的同时大幅减小文件大小。
2、PNG
PNG(Portable Network Graphics)格式是一种位图图像文件格式,以其优秀的压缩能力和对图像质量的无损保存而受到青睐。PNG支持透明度(alpha channel),这使得它在网页设计中尤其有用。
3、GIF
GIF(Graphics Interchange Format)格式是一种基于矢量的图像文件格式,广泛用于网络上的动画和简单图形,支持透明背景和多种颜色的索引颜色模型。GIF格式的主要特点是其动画功能,允许将一系列帧组合成一个动画,这使得它在早期网页设计中非常流行。然而,由于GIF的色深限制(通常为256色),它不适合保存高质量的照片或需要广泛色彩范围的图像。
4、TIFF
TIFF(Tagged Image File Format)格式是一种灵活且广泛使用的图像文件格式,主要用于存储高分辨率的栅格图像(工业印刷场景),如照片和艺术图形。TIFF支持多种颜色和数据类型,包括黑白、灰度、RGB和CMYK,以及无损和有损压缩选项,使其适用于需要高质量图像保留的专业打印、地理信息系统(GIS)和医学成像等领域。TIFF文件的扩展名通常是.tif或.tiff。
RGB色彩模型由红色、绿色、蓝色三个色彩通道组成,通过三原色混合表示其他颜色。
8位色深的RGB模型中,每一种颜色可分为0-255共256个等级,即每个通道2的8次方个色阶。
在RGB模型中,三个通道的值为0时,图像为纯黑色,三个通道的值为255时,图像为纯白色。
在CMYK模型中,三个通道的值0%时,图像为纯白色,三个通道的值100%时,图像为纯黑色。
Sobel算子是一种经典的边缘检测算法,用于计算图像在水平方向(x方向)和垂直方向(y方向)的梯度强度和方向。它通过卷积核强调边缘区域的高频信息,能够在保留边缘细节的同时减少噪声对结果的影响。Sobel算子计算简单,适用于检测图像中的边缘轮廓。
Laplacian算子是一种二阶导数算子,主要用于检测图像中的边缘和细节。它通过计算像素与周围像素的差异,强调图像中的高频成分,从而突出边缘区域。与Sobel算子不同,Laplacian算子不区分方向,它同时检测水平、垂直和对角线方向的边缘。由于其对噪声较为敏感,通常需要先对图像进行平滑处理。Laplacian算子在图像锐化和边缘检测中有广泛应用。
卷积是将一个小型矩阵,即卷积核,沿着整个图像滑动,与图像的局部区域进行元素间的乘积求和,以此计算卷积结果。
在卷积操作中,步长(Strides)控制着卷积核滑动的距离,当步长为1时,卷积核每次滑动1个像素。
在卷积操作中,填充(Padding)是指在输入图像的边缘添加额外的像素值(通常为零),以确保卷积核能够在图像的边界处也进行计算,从而保持输出特征图的尺寸与原图尺寸大小一致。
池化(Pooling)是卷积神经网络中常用的一种下采样操作,旨在减少特征图的尺寸,同时保留重要的信息。池化通过对局部区域应用某种统计操作(如最大值或平均值)来简化特征图。常见的池化方式有最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化选取局部区域中的最大值,而平均池化则计算局部区域的平均值。池化操作可以有效减少计算量、防止过拟合,并增强模型的平移不变性。
假设矩阵如下:
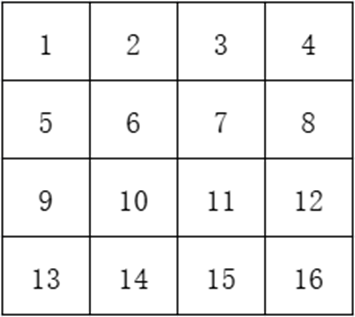
如果进行步长为2 的最大值池化,则先将矩阵分割为2*2的小矩阵:
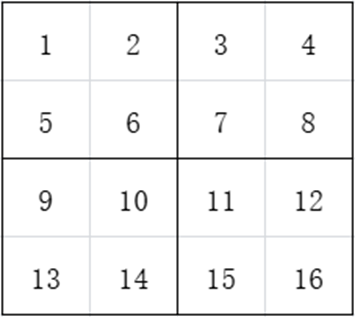
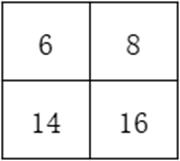
如何再选取每个区域的最大值,结果为:
线性回归与梯度下降
监督学习是一种机器学习方法,其特点是利用带有标签的数据集训练模型,以便模型能够预测新数据的标签。 这些标签被称为“监督”,因为它们指导着模型的学习过程。
无监督学习是一种机器学习方法,其特点是 利用未标记的数据集训练模型,旨在从数据中发现隐藏的结构、模式或关系。 由于没有预先定义的标签,模型需要自行探索数据中的规律。
强化学习是一种机器学习方法,其特点是通过试错机制来学习最优行为策略。模型在与环境交互的过程中,根据其采取的行动获得奖励或惩罚,并以此调整自己的行为策略,最终目标是最大化累积的奖励。
决策树是一种简单易懂的机器学习算法,其特点是用树状结构来表示分类或回归规则。每个节点代表一个特征,分支代表不同的特征取值,叶子节点代表最终的预测结果。 决策树能够直观地展现决策过程,并且容易解释和理解,但是决策树算法容易过拟合。
朴素贝叶斯分类是一种基于贝叶斯定理的简单高效的分类算法,假设特征之间相互独立。尽管这一假设在许多实际场景中并不完全成立,但朴素贝叶斯在处理高维数据和文本分类(如垃圾邮件检测)等问题时表现出色。它具有计算复杂度低、训练速度快的特点,适用于小数据集,但对特征独立性假设的依赖可能限制其在某些复杂场景中的准确性。
K 均值聚类算法是一种无监督学习方法,旨在将数据点划分为 K 个簇。其特点是 通过迭代地计算每个数据点的均值向量来确定每个簇的中心,并将数据点分配到与其距离最近的簇中。K 均值算法简单易行,但需要提前设定簇数 K,并且容易受到初始中心点的选择影响。
线性回归是一种监督学习算法,用于预测连续目标变量。其特点在于 假设目标变量与特征变量之间存在一个线性关系,并通过最小化预测值与真实值的误差来确定最佳的回归系数。线性回归模型简单易懂,并且可解释性强,但它假设数据服从线性分布,在非线性关系下效果不佳。
梯度下降是一种优化算法,用于通过迭代方式最小化目标函数。它通过计算目标函数对模型参数的梯度,沿着梯度下降的方向更新参数,直到达到最优值或接近最优值。梯度下降简单高效,适用于大多数机器学习模型的训练,但对学习率的选择敏感,学习率过大可能导致发散,过小则收敛缓慢。
学习率(Learning Rate)是深度学习中优化算法的一个重要超参数,决定了在每次参数更新时,模型权重调整的步伐大小。较高的学习率可能导致模型训练不稳定,甚至发散;而较低的学习率则可能使训练过程过慢,陷入局部最优解。因此,选择合适的学习率对于模型的收敛速度和最终性能至关重要。
损失函数是机器学习算法中一个关键概念,用于衡量算法预测结果与真实值之间的差异。其特点在于 描述了预测错误程度,越小表示预测越准确。损失函数可以根据不同的问题类型选择不同,如平方误差、交叉熵等,每种损失函数都有其特定使用场景和优缺点。
神经网络基础
人工神经网络(ANN)由以下部分组成:
输入层:这些层接收自变量作为输入
隐藏层(中间层):这些层连接输入层和输出层,同时对输入数据进行转换。此外,隐藏层包含节点,它们将输入值转换为更高/更低维度的值。通过使用激活函数来激活中间层节点的值,实现了更复杂表示的功能
输出层:这一层生成输入变量通过网络传递后预期产生的结果
正向传播是人工神经网络训练过程中的一步,负责将输入数据传递到输出层,并计算最终预测结果。其特点在于 逐层地将输入信号通过激活函数处理,并将处理后的信号作为下一层的输入,直到得到最终的输出。正向传播的过程本质上就是神经网络模型的执行过程,用于生成模型对输入数据的预测。
激活函数是人工神经网络中一个至关重要的组成部分,它负责将输入信号传递到下一层神经元时进行变换。它的特点在于能够引入非线性关系,使得简单线性组合可以模拟出更复杂的功能映射。正是由于这种非线性的特性,神经网络才能学习复杂的模式、解决非线性问题,并展现出强大的泛化能力。
反向传播是一种用于训练人工神经网络的优化算法,其核心特点在于通过计算损失函数对每个参数的梯度,并利用梯度下降法更新参数值,从而逐步降低模型的预测误差。这一过程涉及遍历整个神经网络,从输出层向输入层逐层计算梯度信息,尽管计算量较大,但它能够高效地训练复杂的深度学习模型。反向传播的关键在于利用链式法则来高效计算梯度,反向传递误差,并迭代更新权重以最小化损失函数,使神经网络能够学习如何调整内部参数以改善性能。
基于神经网络的图像分类
数据缩放是指将特征值变换到一个特定范围,通常是0到1之间。这种操作可以显著影响模型的准确度。
因为许多机器学习算法,例如梯度下降法,对数据的尺度很敏感。如果数据的尺度差异很大,会导致算法在训练过程中对某些特征的更新速度远快于其他特征,从而影响模型的收敛速度和最终性能。适当的缩放可以加快收敛速度,提高模型的稳定性和准确度。
迁移学习是一种机器学习技术,它允许模型将在一个任务上学习到的知识应用到另一个相关任务上。这种学习方式的特点是能够利用已有的模型和数据,减少对大量标注数据的需求,加速模型训练过程,并提高模型在新任务上的性能。迁移学习特别适用于数据稀缺或标注成本高昂的场景,它通过调整预训练模型来适应新任务,实现知识的有效迁移。
目标检测基础
Selective Search算法是一种用于目标检测的候选区域生成方法。它通过图像分割将图像划分为多个区域,然后根据颜色、纹理、大小和形状等特征相似性进行合并,最终生成一系列可能包含目标物体的候选区域。
IoU(Intersection over Union)是一种用于评估两个多边形或区域重叠程度的指标,它是计算两个区域交集面积与它们的并集面积之比。 IoU 值范围从 0 到 1,数值越大表示两个区域之间的重叠程度越大。
非极大值抑制常用于目标检测中消除冗余框。它通过筛选预测框的置信度和位置,保留置信度得分最高的预测框,并移除与其重叠度较大的其他框,从而减少重复检测。
RCNN模型详细的训练过程:
- 用于训练的数据集中包含对象的类别和真实边界框
- 使用SelectiveSearch算法,生成候选区域,生成的候选区域要足够多,以免漏掉某些对象
- 将候选区域与每一个真实边界框计算交并比(IoU)
- 将候选区域的类别指定为,IoU最大且大于一个阈值的真实框的类别,并计算候选区域与给真实框的偏移量
- 使用非极大值抑制,丢弃重叠的边界框,只保留置信度最大的边界框
- 将候选区域尺寸调整为224*224,然后传入预训练模型(VGG16),然后通过全连接层输出为预测类别和预测偏移量
- 将输出的预测类别和预测偏移量与第4步产生的类别和偏移量计算损失值
- 通过梯度下降,调整模型参数,直到训练完成
图像语义分割
图像语义分割是一种像素级别的分类,旨在为图像中的每个像素分配一个类别标签,从而识别并分割出图像中不同的对象和场景。这种像素级别的分类使得模型能够理解图像内容的详细结构,区分出人、车辆、建筑物等不同实体,以及它们所属的类别。
图像语义分割在自动驾驶、医疗影像分析、机器人导航等领域具有重要应用价值。
图像语义分割在训练模型时需要使用像素级别标注的数据集。
图像语义分割常用数据集:
PASCAL VOC: 提供像素级标注,适用于语义分割任务。
Cityscapes: 城市场景语义分割数据集,特别适合自动驾驶领域。
ADE20K: 一个通用的场景分割数据集,包含大量类别。
图像生成
图像生成(Image Generation)是一种计算机视觉任务,其目的是根据输入生成具有目标图像性质的图像。
自编码器是一种无监督学习的神经网络模型,主要用于数据降维和特征学习。它由两个主要部分组成:编码器和解码器。编码器将输入数据压缩成一个低维的潜在表示(向量),而解码器则从这个潜在表示(向量)重建出原始数据。自编码器的目标是最小化输入数据与重建数据之间的差异,从而学习到数据的有效表示。
变分自编码器(VAE)是一种改进的自编码器模型,它是一种结合了概率模型与神经网络的深度学习架构,其目的是通过学习数据的概率分布来生成新的样本。VAE由一个编码器将输入数据映射到潜在变量的概率分布上,再通过解码器从该分布中采样并重构原始数据。这种设计使得VAE不仅能够进行降维和特征提取,还能生成具有类似统计特性的新图像或数据点。
生成对抗网络(GAN)是一种深度学习架构,由Ian Goodfellow等人在2014年提出。它包含两个关键组件:生成器(Generator)和判别器(Discriminator)。生成器的目标是从随机噪声中生成与真实数据相似的数据,而判别器则尝试区分生成的数据和真实数据。这两个网络通过对抗式学习相互竞争:生成器努力生成越来越逼真的数据以“欺骗”判别器,而判别器则不断改进以更准确地识别真实与生成的数据。通过这种对抗训练,生成器最终能够产生高质量、难以区分真假的数据。GAN在图像生成、文本生成和音频生成等领域有非常出色的表现。
今天也要加油鸭
